大佬 Aleksa Gordić (水平问题) 刚发了篇深度长文《Transformer 内部:一个 Token 的一生》, 带你深入解析现代稠密 Transformer:YaRN、混合注意力、soft capping、QK normalization、FLOPs/token、集群规模估算等地址:www.aleksagordic.com/blog/transformer
“在这篇文章中,我会深入介绍现代稠密 Transformer 的内部机制。我将只关注单块 GPU 上的前向传播,就像我们即将执行一个训练步骤一样,同时忽略反向传播和分布式系统细节。实践中,大型 Transformer 在训练和推理时通常都会分布在多台设备上。
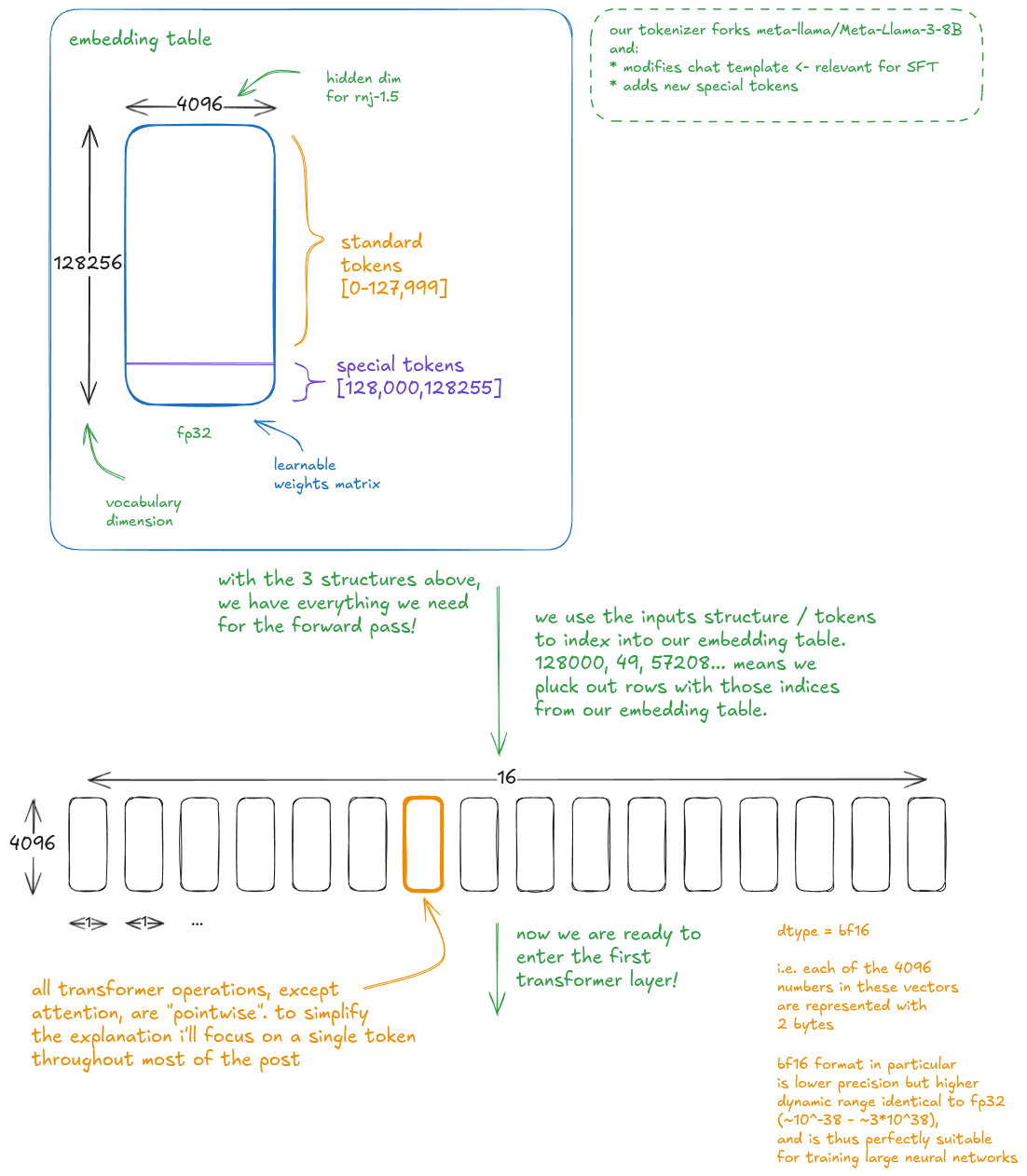
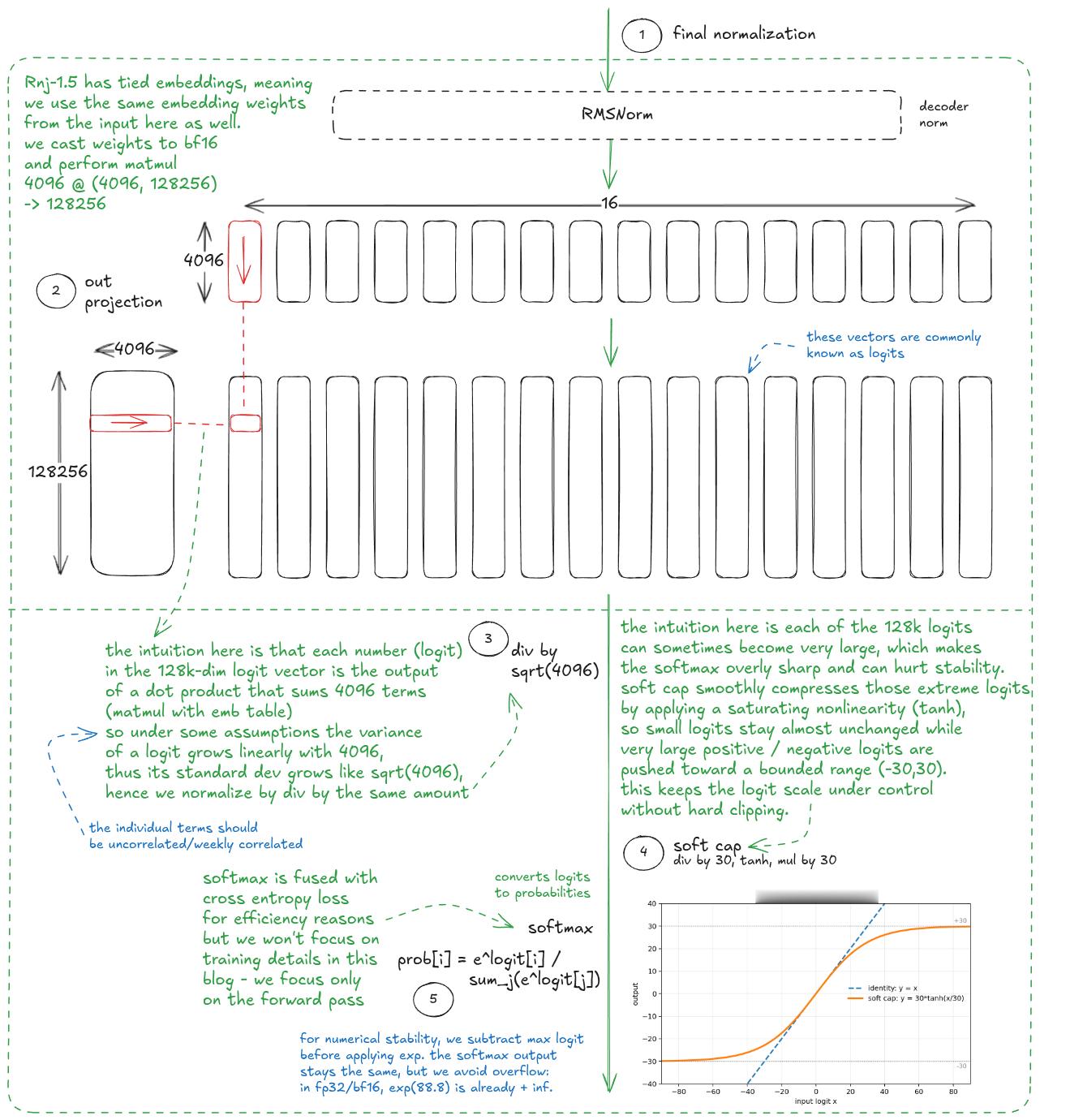
作为贯穿全文的例子,我会使用 Rnj 1.5 的确切架构。这是我和 Ashish Vaswani 的 AI Lab(Essential AI Labs)团队一起做过的一个模型。我们本周发布了它,并在 Hugging Face 上开放了权重。
本文分为七个部分:
Transformer 前向传播:一个 token 的高层流程RMSNorm:归一化层GeGLU MLP:GELU 门控前馈模块MHA:多头自注意力YaRN:用于长上下文的位置嵌入Core Attention:全局注意力 + 块内局部注意力Transformer 数学:FLOPs/token、集群规模估算等”AI创造营