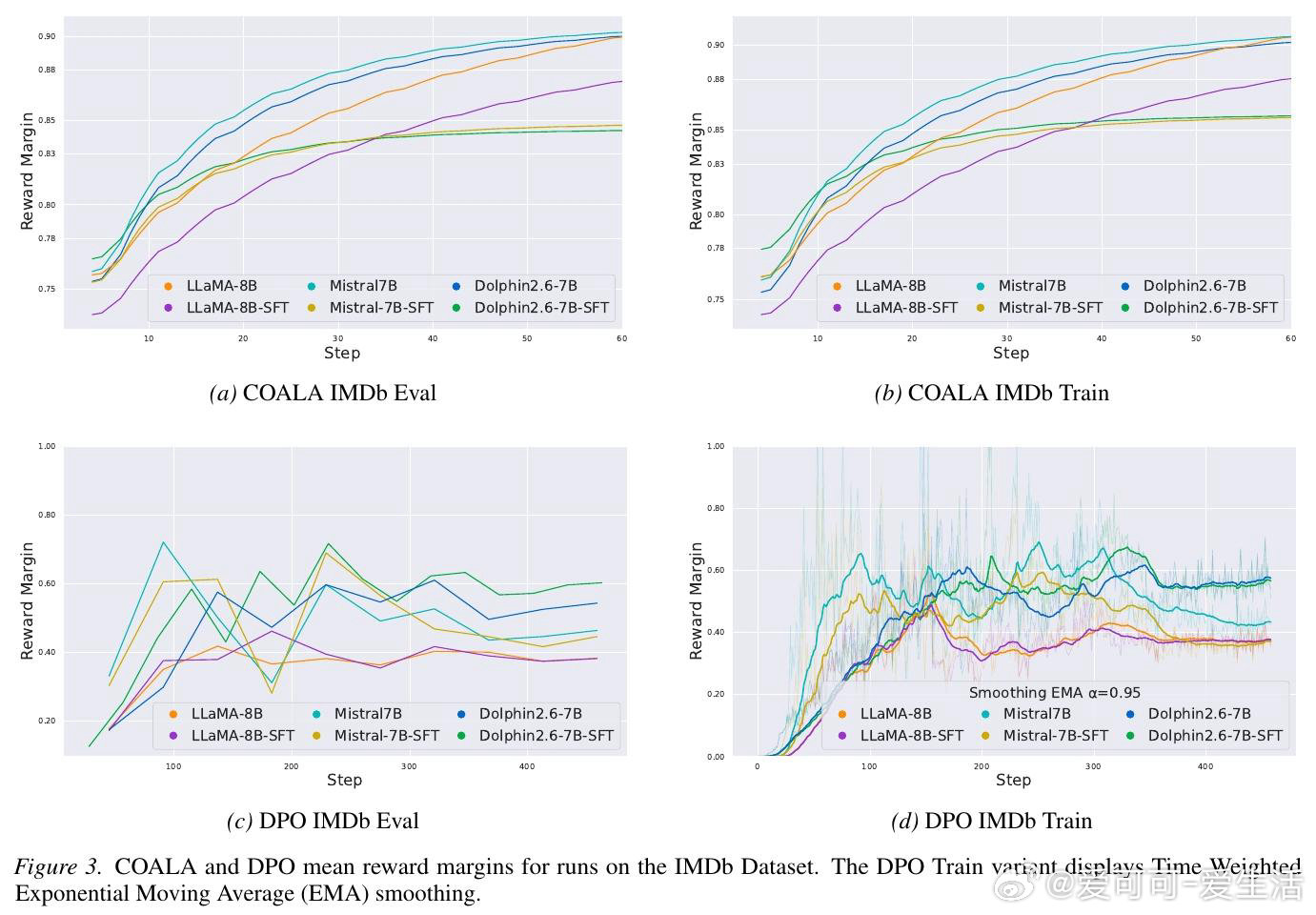
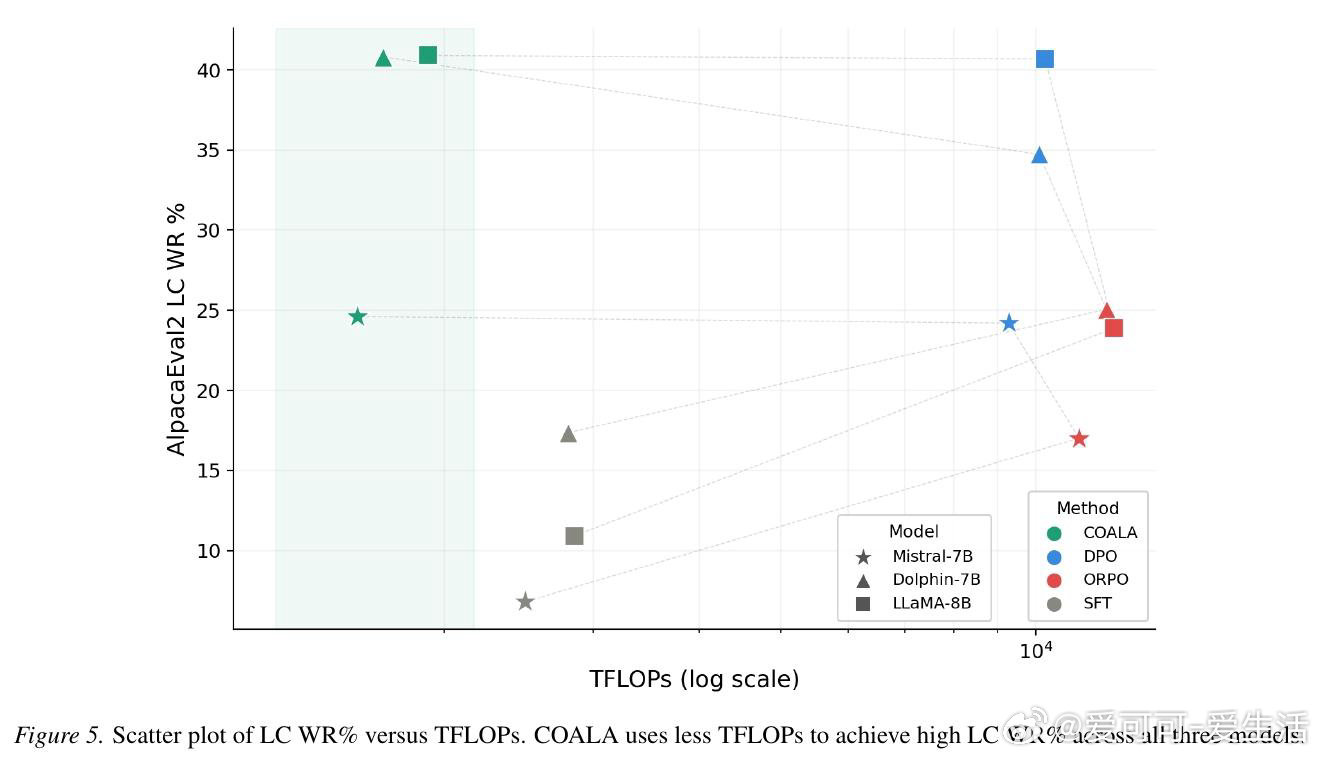
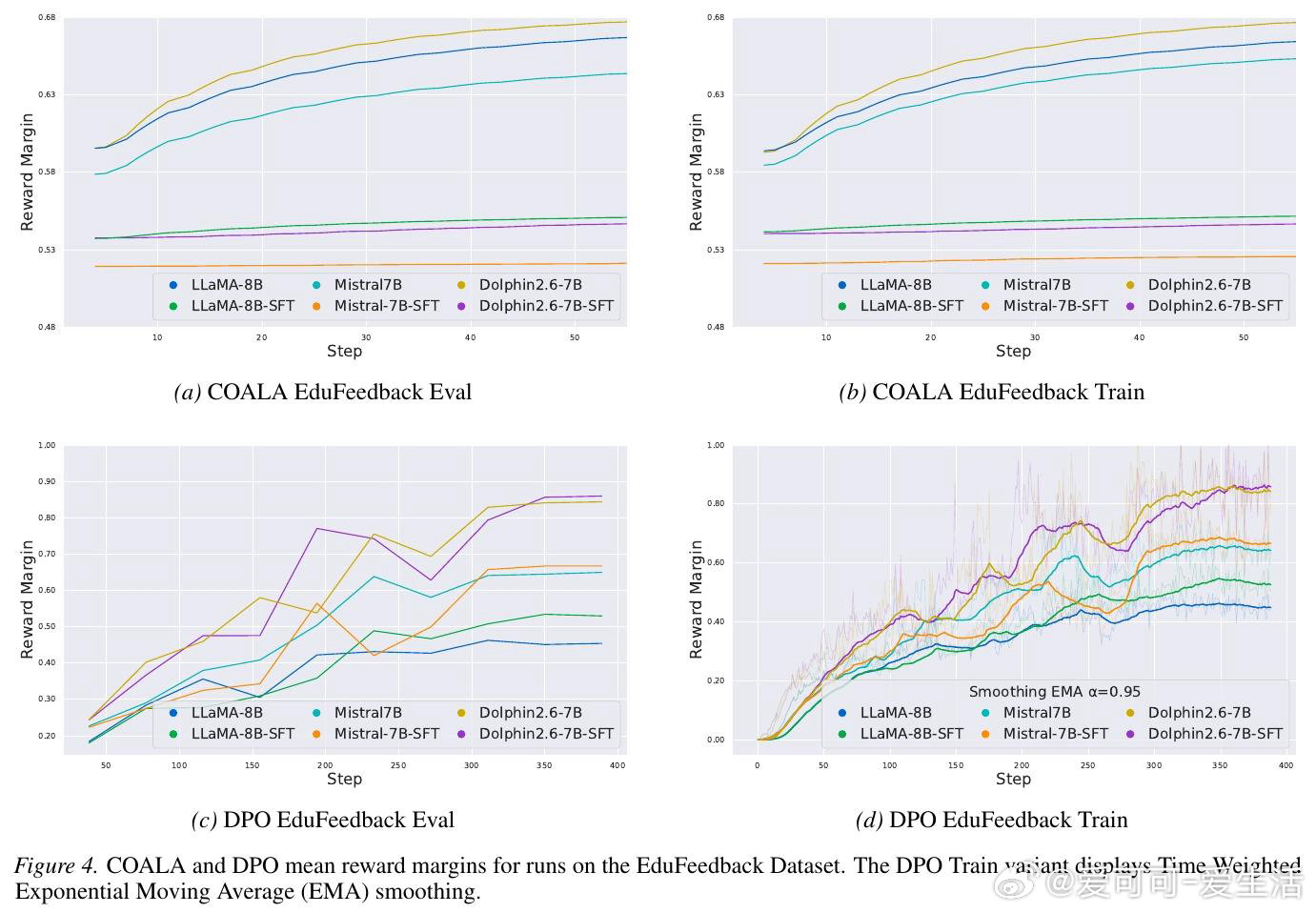
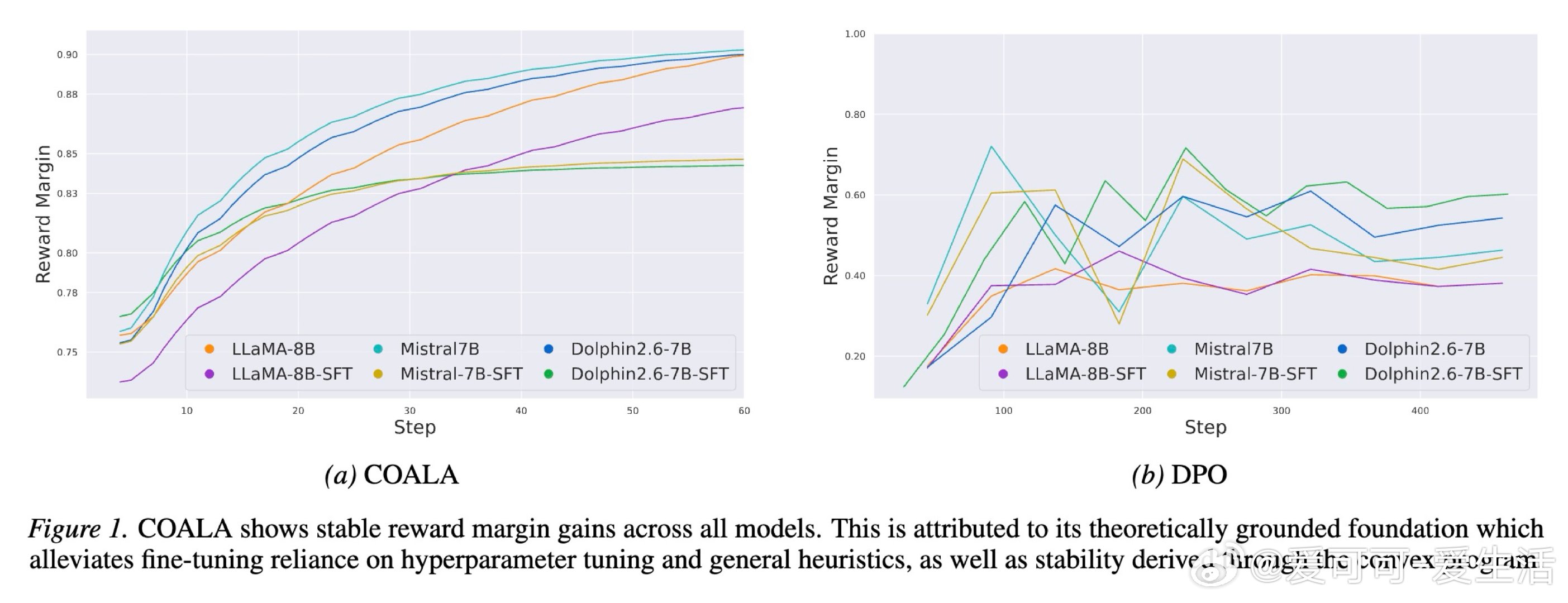
[LG]《Convex Optimization for Alignment and Preference Learning on a Single GPU》M Feng, M Pilanci [Stanford University] (2026)
在偏好对齐领域,DPO虽比RLHF简单,却仍吃显存、依赖参考模型和调参。根因是把排序学习塞进非凸训练,稳定性靠经验配方维持。
本文的核心洞见是:把偏好对齐重新看作凸分类问题。由此,在冻结LLM特征上训练凸神经网络头,用ADMM求解,去掉参考模型。
这项工作留下的遗产是把单卡对齐变成可收敛的优化流程。它打开的新门是低资源、本地化偏好微调;尚未跨过的门槛是冻结底座难学深层语义偏移。
arxiv.org/abs/2605.23244 机器学习 人工智能 论文 AI创造营