同样用 GPT-5 和 Claude,为什么 Cursor 比别人强这么多?
答案不在模型,在模型外面那层壳。
最近看到一个数据很震惊:Cursor 自家代码仓库里,35% 的 PR 已经由 AI 自主完成了——不是补全代码,是 AI 独立写功能、自己测试、解决合并冲突、录制操作视频当证明,然后把完整 PR 交给人类审核。
而 Claude Code 和 OpenAI Codex 用的是同一批模型,结果差这么远,为什么?
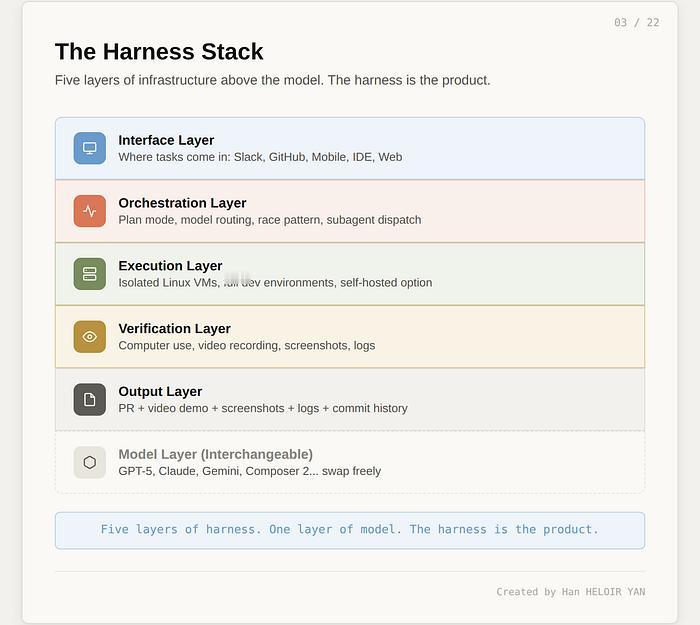
因为模型只是发动机,框架才是整辆车。
Cursor 在模型外面搭了五层:任务怎么进来、怎么拆解分配、在哪台机器上跑、怎么验证结果、最终交付什么。最关键的是验证层——Agent 会真的打开浏览器,像人一样点按钮、填表单、检查页面有没有渲染正确,发现问题就回去改代码,改完再测,直到通过,全程录屏。
更绝的是,Cursor 会把同一个问题同时丢给多个模型,谁答得好用谁——模型成了参赛选手,框架才是规则制定者。
Claude Code 走的是完全不同的路:代码留在本地,不上云,擅长啃一个复杂的大任务,上下文窗口超长,做架构级重构很能打,但没有视频证明、没有并行。
Codex 更简单粗暴:从 GitHub Issue 出发,直接出 PR,适合流程简单、任务定义清晰的团队。
三个工具,同款模型,体验差这么多,本质就一句话:模型已经商品化了,框架才是护城河。
Cursor 估值 293 亿美元,卖的不是 Claude API 的转发权,卖的是那套让 AI 真正能干活、能证明自己干了活的执行体系。
所以以后选 AI 编程工具,别只问"哪个模型最强",要问的是——哪套框架最适合你团队的工作方式?